
Hay muchos blogs y videos en línea que le muestran las respuestas a los problemas de leetcode. Sin embargo, la perspectiva es principalmente como entrevistador, y no como candidato.
En mis 25 años en Big Tech, he realizado más de mil entrevistas (en Amazon como entrenador de bar, cientos en Microsoft y un poco menos de cien en Google).

Big Tech tiene 3 tipos de entrevistas para ingenieros de software: [1] codificación, [2] diseño de sistemas, [3] liderazgo, habilidades blandas, cultura, etc. El ciclo tiende a fusionarlos. Por ejemplo, un SDE-I puede tener 3 de codificación, 1 de diseño, 1 de liderazgo, mientras que un ingeniero principal puede tener 1 de codificación, 2 de diseño, 3 de liderazgo. Personalmente, prefiero entrevistas de liderazgo más abiertas, ya que siento que de esta manera aprendo más sobre el candidato. Sin embargo, las entrevistas de codificación son un mal necesario.
Ahora, un descargo de responsabilidad: todas las preguntas de entrevistas de codificación son malas, incluidas las mías. Tienes 45 minutos para hacer una propuesta de alquiler que podría cambiar la vida de alguien. La gente nunca está: esto es estresante, están agotados y hay un límite de tiempo artificial. Estas preguntas están diseñadas para ajustarse al marco de tiempo y obtener señales específicas. Tienden a ser preguntas más simples que conducen a conversaciones de alta calidad, donde puedo entender el pensamiento de alguien. La conversación es mucho más importante para mí que el código real que mi candidato escribe en la pizarra. ¿Qué compensaciones existen? ¿Cómo equilibras entre ellas? Como entrevistador, sé cómo ayudar a mis candidatos a tener una buena experiencia, cuándo guiar, cuándo explorar y cómo calibrar mis expectativas sobre un entorno artificial.
Para las entrevistas de codificación, a menudo planteo variaciones de las siguientes preguntas, basadas en cosas que tengo que hacer en la vida real. Dado que decidí retirarme de esta pregunta, hoy la desglosaré. ¿Qué estoy buscando? ¿Qué veo que hace el candidato?
Supongamos que tenemos un sitio web, y rastreamos las páginas que los clientes están viendo, como métricas comerciales.
Cada vez que alguien visita el sitio, escribimos un registro en un archivo de registro compuesto por una marca de tiempo, PageID y CustomerID. En última instancia, tenemos un gran archivo de registro con muchas entradas en ese formato. Cada día tenemos un nuevo archivo.
Ahora, dados dos archivos de registro (el archivo de registro del día 1 y el archivo de registro del día 2), queremos generar una lista de "clientes leales" que cumplan con los siguientes criterios: (a) han visitado al menos dos páginas únicas en ambos días.
Esta pregunta no es particularmente difícil, pero requiere algo de pensamiento y comprensión de la complejidad del código y las estructuras de datos. Puedes obtener fácilmente los clientes de los dos días, puedes obtener fácilmente los clientes que han visto al menos dos páginas únicas, pero obtener la intersección de ambos eficazmente requiere más trabajo.
He preguntado esto tal vez 500 veces, lo que me permite calibrar bien. He encontrado que la decisión de alquiler de esta pregunta se alinea con la decisión final de alquiler en el ciclo final para el candidato. También puedo elevarlo a candidatos de niveles más altos, lo que le da un amplio uso, y puedo ofrecer muchas pistas a los candidatos que luchan.
Hacer preguntas de aclaración
Los grandes candidatos deben hacer preguntas de aclaración antes de saltar a la codificación. Quiero ver que mis candidatos tengan algo de intuición, ya que en realidad expreso la pregunta de manera ambiguo.
¿Me refiero a diariamente oen general 2 páginas únicas?
Esto afecta significativamente la solución. Me refiero a "en general 2 páginas", ya que es una pregunta más interesante. Aproximadamente la mitad de los candidatos saltan directamente a la codificación sin aclarar esto, y de esa mitad, muchos asumen erróneamente que me refiero a "2 páginas únicas por día". Si es un candidato más junior, daré muchas pistas antes de que comiencen a codificar. Si es un candidato más senior, esperaré un poco para ver si piensan más profundamente sobre el algoritmo.
En la vida real, los ingenieros siempre están lidiando con la ambigüedad, y la mayoría de los problemas de software se remontan a requisitos mal definidos. Por lo tanto, quiero obtener señales sobre cómo descubrir y manejar la ambigüedad.
Otra pregunta de aclaración es que el 90% de las personas se pierden la expectativa, pero también es importante: ¿y las repeticiones? ¿Visitar la misma página el mismo día? ¿Visitar la misma página en diferentes días? Para esta pregunta, esas son repeticiones.
Otra pregunta importante es ¿qué escala estamos hablando aquí? ¿Los datos caben en memoria? ¿Puedo cargar el contenido de uno de estos archivos en memoria? ¿Puedo cargar el contenido de ambos?
La inspiración para esta pregunta proviene de un sistema del mundo real en el que trabajé en Amazon (llamado ClickStream), que se encarga de rastrear el comportamiento del usuario en Amazon.com. Procesamos eventos de millones de clientes concurrentes, en un gigantesco clúster de MapReduce de 10,000 hosts, con todo un equipo de ingenieros manteniéndolo y operándolo. Sin embargo, para los propósitos de una entrevista de 45 minutos, imagina que los datos caben en memoria, y el alcance es mucho más pequeño.
Finalmente, una pregunta importante es, la pregunta importante ¿es el rendimiento más importante que la memoria y la mantenibilidad? Hay una solución ingenua con un tiempo de ejecución de O(1) en memoria, pero solo O(n) en tiempo de ejecución. Hay una mejor solución con un tiempo de ejecución de O(n), pero O(n) en memoria. Y hay una solución intermedia que hace un preprocesamiento en O(n log N) usando O(n log n) en memoria, y luego el algoritmo principal es O(n), usando O(1) en memoria. Todos tienen pros y contras. Algunos métodos heurísticos que puedes usar para mejorar el rendimiento o el uso de memoria pueden hacer que el código sea más difícil de leer y desarrollar más adelante. En candidatos más avanzados, espero discutir sobre esto.
Primero la solución ingenua
Teóricamente, podrías escribir una consulta SQL muy simple, y es seguro que las grandes empresas tecnológicas tienen enormes almacenes de datos donde podrías hacer esto fácilmente. Pero, para el alcance de una entrevista de codificación, no querrías hacerlo. Dado que esto no es un problema de sistema distribuido y los datos caben en memoria, ¿por qué lidiar con la complejidad y las dependencias adicionales de una base de datos cuando puedes resolverlo con 20 líneas de código simple?
Punto de partida:
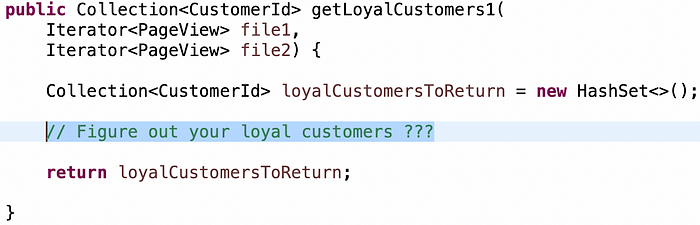
Aproximadamente el 80% de los candidatos eligen primero la solución ingenua. Esto es "para cada elemento en el archivo 1, bucle a través de todo en el archivo 2, buscando elementos con el mismo CustomerID y rastreando las páginas que han visto."
El problema de la solución ingenua es que su tiempo de ejecución es O(n²).
No me importa obtener primero la solución ingenua, pero realmente quiero ver que mis candidatos tengan un momento AHA donde O(n²) probablemente nunca será bueno. Espero que ese momento llegue rápidamente sin pistas. A menos que haya restricciones de memoria u otras que no se pueden manejar dinámicamente, no se debe conformar con un algoritmo O(n²).
Después de que el candidato proponga O(n²), sonrío cortésmente y espero. Realmente espero que la siguiente palabra que salga de su boca sea "… pero esta es la complejidad O(n², así que ¿puedo hacerlo mejor?" Si no, indagaré "¿cuál es el tiempo de ejecución de esta solución?" En la mayoría de los casos, el candidato tendrá su momento AHA después de la insinuación y continuará hacia una mejor solución.
Afina O(n²) a O(n)
En este punto, necesitas considerar qué estructuras de datos usar y cómo almacenar los datos.
Los pobres candidatos van por listas enlazadas o arreglos. Estos tienen O(n) de búsqueda, así que, sin importar cuánto lo intenten, volverán al algoritmo O(n²). Puedes usar árboles, pero dado que la búsqueda es O(log n), eso puede resultar en O(n log n) en total como lo mejor.
La intuición de los mejores candidatos es que un mapa proporcionará O(1) de búsqueda, y necesitan convertir el algoritmo O(n²) en un algoritmo O(n). Los grandes candidatos señalarán proactivamente que el inconveniente es que usarán O(n) de memoria. Si quieres tener una actitud más peculiar sobre esto, incluso puedes señalar el costo implícito de ejecutar la función hash en el mapa una y otra vez, lo que puede ser costoso. En general, un tiempo de ejecución más rápido a costa de más memoria es un buen compromiso.
Si usas un mapa, ¿cuál es tu clave? ¿Cuál es tu valor? Aquí veo una variedad de respuestas. Algunos candidatos usarán pageID como clave y customerId como valor, pero eso no ayudará. Luego, el candidato cambiará a usar CustomerID como clave y PageID como valor del mapa. Pero eso tampoco es particularmente bueno, ya que ignora el hecho de que puedes tener muchas páginas por cada cliente, no solo una. La intuición de algunos candidatos es que necesitan un conjunto de páginas como valor del mapa, pero elegirán una lista, lo que me hace sentir triste porque ignora el hecho de que puedes tener duplicados. Esta es una buena oportunidad para explorar el conocimiento de estructuras de datos sobre listas frente a conjuntos, ya que el candidato considera cómo manejar duplicados.
Por lo tanto, mapa<customerId, conjunto<pageid>> funcionará. Pero, ¿cargarás el contenido de ambos archivos en un mapa? ¿O tendrás dos mapas, uno para cada archivo? O, ¿puedes cargar solo el contenido del archivo 1 en el mapa y procesar el archivo 2 sin almacenarlo?
Los grandes candidatos se dan cuenta de que pueden optar inmediatamente por la opción número 3. Esto es mucho menos y un algoritmo más simple. Los buenos candidatos llegan allí, pero necesitan un poco de insinuación.
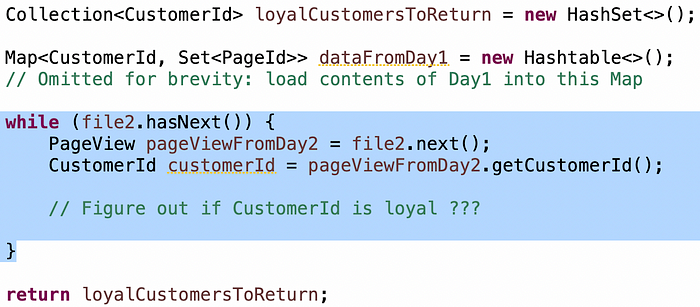
La condición de "clientes que vinieron en dos días" es muy simple: cuando lees las entradas de clientes del día 2, si el cliente estaba en el mapa desde el día 1, entonces sabes que han venido ambos días:
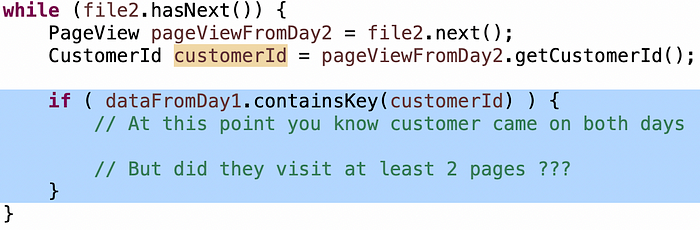
La condición de "clientes que visitaron al menos 2 páginas únicas" a menudo es más difícil de que los candidatos la acierten, así que si se quedan atascados, lanzo una pequeña pista: tienes un conjunto de páginas desde el día 1 hasta el día 2... ¿cómo determinas que son al menos dos páginas únicas?
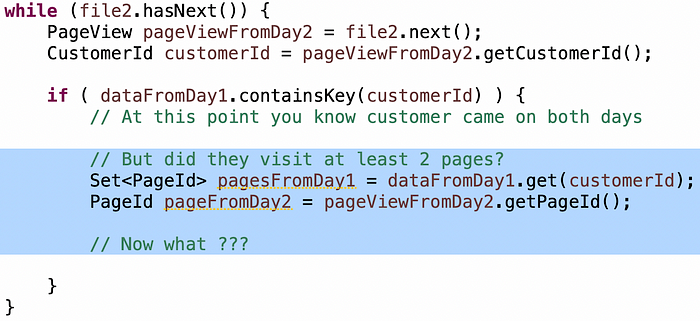
Los pobres candidatos recorrerán los elementos en el conjunto para verificar si las páginas del día 2 están allí. Esto nuevamente convierte tu algoritmo O(n) en O(n²). La cantidad de candidatos que hacen esto es sorprendente. Los mejores candidatos usarán .contains() (1) en el conjunto hash. Pero la lógica sigue estando ahí.
La intuición correcta es: si estás dentro, si el cliente visitó al menos dos páginas el día 1, y visitó cualquier página el día 2, sin importar qué página visitaron el día 2, son leales. De lo contrario, solo visitaron una página el día 1, así que la pregunta es: ¿es otra página? Si es así, son leales, de lo contrario, es un duplicado, así que no lo sabes y deberías seguir adelante.
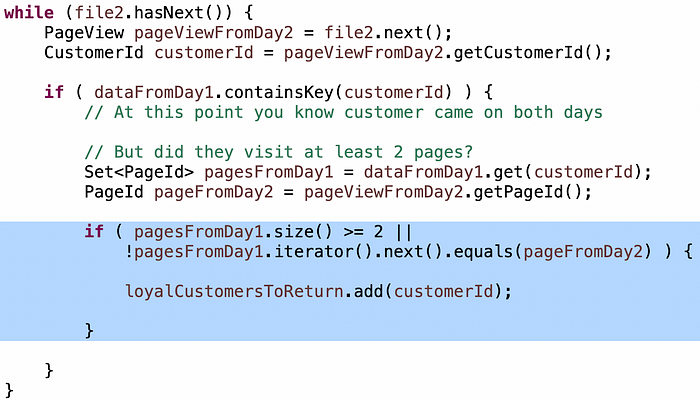
Necesitas prestar atención a los detalles, como usar ">" en lugar de ">=" o perder "!" en la segunda cláusula. A menudo veo esto. No me preocupo. Los grandes candidatos revisan cuidadosamente su trabajo al finalizar el algoritmo y rápidamente se dan cuenta de ellos. Los buenos candidatos, después de un poco de insinuación, los descubren. Esto me da una buena señal de habilidades de depuración.
Optimización de la solución
Si los candidatos llegan a este punto y tenemos algo de tiempo extra, entonces es bueno explorar cómo optimizar la velocidad o el uso de memoria. La discusión sobre estos compromisos con la mantenibilidad futura es un punto extra.
Por ejemplo, si la memoria es una restricción, no necesitas mantenercada página del día 1 en el mapa, solo dos, porque la pregunta es "al menos dos páginas", por lo que un conjunto de tamaño 2 o incluso un arreglo de tamaño 2 utilizará menos memoria que un conjunto sin límites.
O, si ya has determinado que el cliente es leal, entonces la próxima vez que encuentres a ese cliente en el día 2, no necesitas desperdiciar ciclos de CPU.
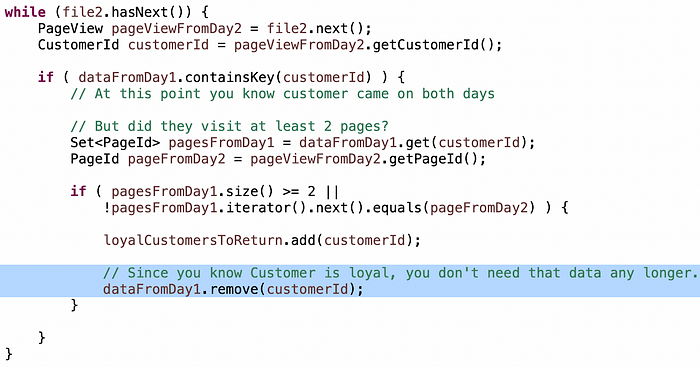
Una frase sobre la optimización: puedes argumentar que si las necesidades futuras cambian, estas optimizaciones hacen que cambiar el algoritmo sea más difícil. Esa es una postura razonable. Siempre que puedas tener una buena conversación sobre los pros y los contras, estoy satisfecho con una discusión de alta calidad sobre cómo equilibrar estas decisiones. Al mismo tiempo, la capacidad de optimizar un algoritmo cuando sea necesario *es una característica de un gran ingeniero que *necesitarás *una o dos veces en tu carrera.
Otra solución
La gran mayoría de los candidatos optan por el enfoque del mapa, pero a veces tengo un candidato que busca otro enfoque. Quizás un máximo del 5%.
¿Qué tal si preprocesas los archivos y los ordenas por CustomerID y luego por PageID?
El preprocesamiento es una herramienta poderosa en tu arsenal de ingeniería de software, especialmente si vas a realizar una serie de operaciones. Puedes tener un golpe de preprocesamiento con el primero, o puedes hacerlo de antemano, lo que amortiza el costo a lo largo del tiempo. Ordenar los archivos puede ser una operación O(n log n) con memoria constante.
Si los archivos están ordenados, el problema se vuelve más fácil y es simplemente un algoritmo de búsqueda binaria, que puedes ejecutar en O(N) usando O(1) en memoria. Moverás los punteros de los archivos 1 y 2 al mismo customerID, lo que significa que han estado ambos días. Dado que la segunda clave es pageID, puedes usar otro algoritmo de búsqueda binaria para determinar si hay al menos dos páginas únicas. Por lo tanto, esto es un algoritmo de búsqueda binaria dentro de otro algoritmo de búsqueda binaria. ¡Es un problema interesante! Dejaré la implementación real como un ejercicio para la audiencia.
En resumen
Espero que esta pequeña visión sobre los problemas de codificación desde la perspectiva del entrevistador, y lo que he visto en candidatos buenos, muy buenos y pobres, sea útil para ti. ¡Buena suerte en tu próxima entrevista!