
您是否曾经考虑过在自己的设备上运行自己的主要语言模型(LLM)或视觉语言模型(VLM)?大概,可能有几个疑问是从零下载东西,管理环境,下载适当的模型的重量,以及设备是否可以处理该模型。
让我们进一步。想象一下,在不比信用卡大的设备上操作自己的LLM或VLM。不可能的?一点也不。换句话说,由于我最后写了这篇文章,因此绝对有可能。
可能,是的。但是你为什么要这样做呢?
在这一点上,Edge的LLM似乎很夸张。但是,这种特定的利基用例应该随着时间的流逝而成熟,并且在边缘设备上运行的所有本地AI解决方案都会开发出一些凉爽的边缘解决方案。
它还推动限制以确认可能的可能性。如果您可以在计算量表的极端边缘运行,则可以在Raspberry Pi和大型和强大的服务器GPU之间运行任何级别。
传统上,Edge AI与计算机视觉密切相关。如果您研究了Edge中LLM和VLM的部署,则该字段已添加了一个令人兴奋的维度。
最重要的是,使用最近获得的Raspberry Pi 5做一些有趣的事情。
那么,如何使用Raspberry Pi实现这一切?使用Orama!
什么是Orama?
Ollama已成为执行个人计算机上本地LLM的最佳解决方案之一,而无需处理从头开始设置内容的麻烦。只有几个命令,您就可以毫无问题地设置所有内容。一切都是自由的类型,它与我在多种设备和模型中的经验非常有用。 REST API可以用于模型推断,因此您可以使用Raspberry Pi将其删除,并根据需要从其他应用程序或设备中拨打它们。

还有一个Ollama Web UI,这是一项美丽的AI UI/UX工作,与Orama无缝执行,并为那些担心命令行界面的人无缝执行。基本上,它是本地Chatgpt接口。
同时,这两个开源软件提供了您认为是本地最佳LLM体验。
Ollama和Ollama Web UI都支持Llava这样的VLM,并为此Edge AI用例打开更多门。
技术要求
所有你需要的是:
- Raspberry Pi 5(或低速设置4)选择适合7B型号的8GB RAM变体。
- SD卡 - 尺寸越大,尺寸越大,模型越多。适当的操作系统,例如Raspbian Bookworm和Ubuntu
- 网络连接
如前所述,Raspberry Pi运行的Orama已经接近硬件光谱的极端。从本质上讲,比带有相似内存能力的Raspberry Pi更强大的设备是理论上执行的Linux分布和本文中所述的模型。
1.安装Orama
要在Raspberry Pi中安装Ollama,请避免使用Docker节省资源。
term
执行上述命令后,显示下图。
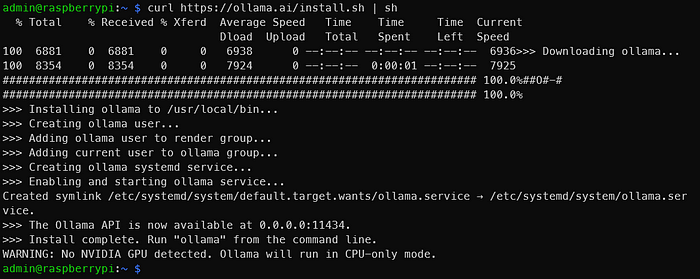
如输出所示,移至0.0.0.0:11434,并确保Ollama正在运行。看到“警告:未检测到Nvidia GPU”是正常的。 Ollama以仅CPU模式执行。这是因为使用覆盆子Pi。但是,如果您遵循这些说明,那应该具有NVIDIA GPU的东西,那就出了点问题。
有关问题和更新,请参见Ollama GitHub存储库。
2.通过命令行运行LLM
有关可以使用Ollama执行的模型列表,请参见官方的Ollama模型库。使用8GB Raspberry Pi,超过7B型号不合适。让我们使用Microsoft 2.7B LLM PHI-2。目前基于MIT许可证。
使用默认的PHI-2模型,但可以自由使用其他标签。查看PHI-2型号页面,以了解如何对话。
term
当显示与以下输出相似的内容时,LLM将使用Raspberry Pi运行!太容易了。
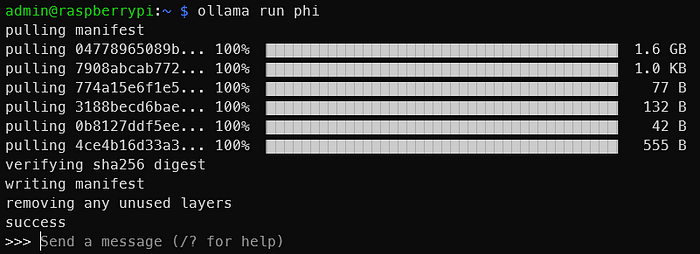

您可以尝试其他型号,例如Mistral和Llama-2。确保SD卡在模型的重量中具有足够的空间。
自然,模型越大,输出越慢。 PHI-2 2.7b每秒可获得大约4个令牌。但是,Mistral 7b每秒下降到大约2个令牌。令牌等同于单词。
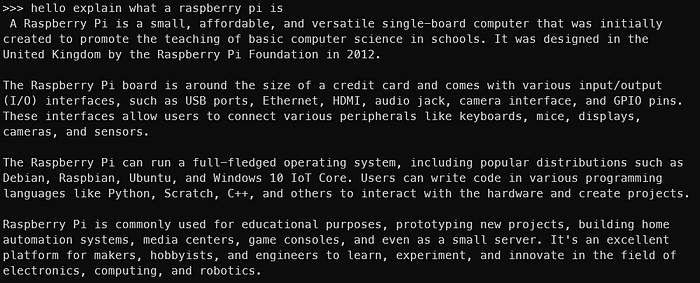
LLM在Raspberry Pi上运行,但尚未完成。终端不适合所有人。 Ollama Web UI也正在运行!
3.安装和执行Ollama Web UI
根据官方的Ollama Web UI GitHub存储库,没有Docker安装。建议将最小Node.js设置为> 20.10,因此请按照> 20.10设置。 Python还建议至少3.11,但是Raspbian OS已经为我们安装。
您需要先安装node.js。 term
如果您需要将来的读者,请将20.x更改为更合适的版本。
接下来,执行下面的代码块。
这是GitHub上提供的内容的一小部分。请注意,Break System Package Flag不会遵循最佳实践,例如使用虚拟环境来简化和简洁。如果找不到乌维科恩的错误,请重新启动终端会话。
如果一切顺利,请从http:// <Raspberry pi本地地址>:8080/http:///0.0.0.0.0.0.0.0:8080 ollama web 8080,您应该能够能够能够,使用权。通过同一网络上的另一个设备访问。

创建帐户并登录时,您会看到与下图相似的内容。
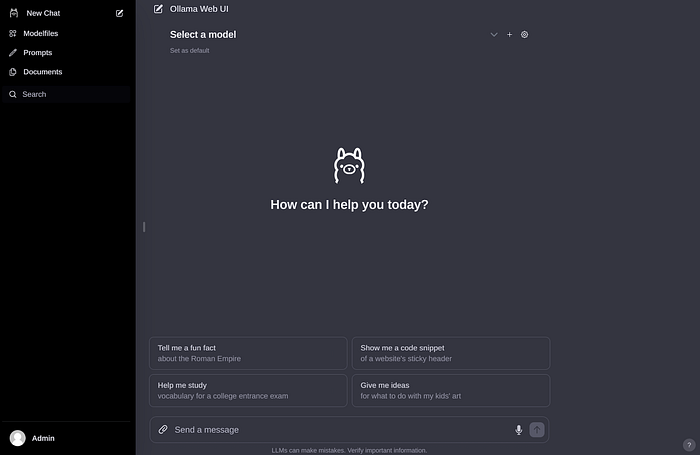
如果您之前下载模型的重量,则将显示在以下Drop -Down菜单中。如果没有,您可以转到设置并下载模型。


我对此没有太多解释,因为整个界面都非常美丽和直观。这是一个非常好制作的开源项目。

4.通过Ollama Web UI执行VLM
如本文开头所述,可以执行VLMS。 Execute Llava是Ollama支持的流行开源VLM。为此,请通过接口绘制“ Llava”以下载重量。
不幸的是,与LLM不同,设置需要大量时间来解释Raspberry Pi图像。以下示例大约需要6分钟的时间进行处理。当时的大多数时间可能是因为事物的图像侧尚未进行优化,但这肯定会在将来发生变化。令牌生成速度约为2令牌/秒。
全部包裹
在这一点上,本文的目标几乎完成了。为了总结,Ollama和Ollama Web UI可以用Raspberry Pi执行LLM和VLM,例如Phi-2,Mismtral和Llava。
您可以想象在Raspberry Pi(其他小边缘设备)上运行的本地主机上有相当数量的LLM用例。 PHI-2大小的模型。
考虑到“大型”名称,“小” LLM和VLM的领域在某种程度上是矛盾的,但它是一个活泼的研究领域,最近具有相当数量的模型。希望这种新的趋势将继续下去,更有效,更紧凑的模型将继续!在接下来的几个月中绝对值得注意。
免责声明:与Ollama或Ollama Web UI没有合作伙伴关系。所有观点和观点都是我自己的,而不是组织。